Spark
Apache Spark is a cluster computing framework designed for fast Hadoop computation. At Crossroad Elf, one of the top companies in Apache Spark, we have a team of expert consultants to use Apache Spark to analyze large amounts of Data.
Spark is an open source framework for running large-scale data analytics applications across clustered computers. It can handle both batch and real-time analytics and data processing workloads.
Spark consists of in-memory cluster computing to increase the processing speed on an application. Spark is based on Hadoop Map Reduce and it extends the Map Reduce model to perform multiple computations. It also includes interactive querying. Spark’s goal was to generalize Map Reduce to support new apps within same engine. With Crossroad Elf, Enterprises can now easily access the power of analytical insights.
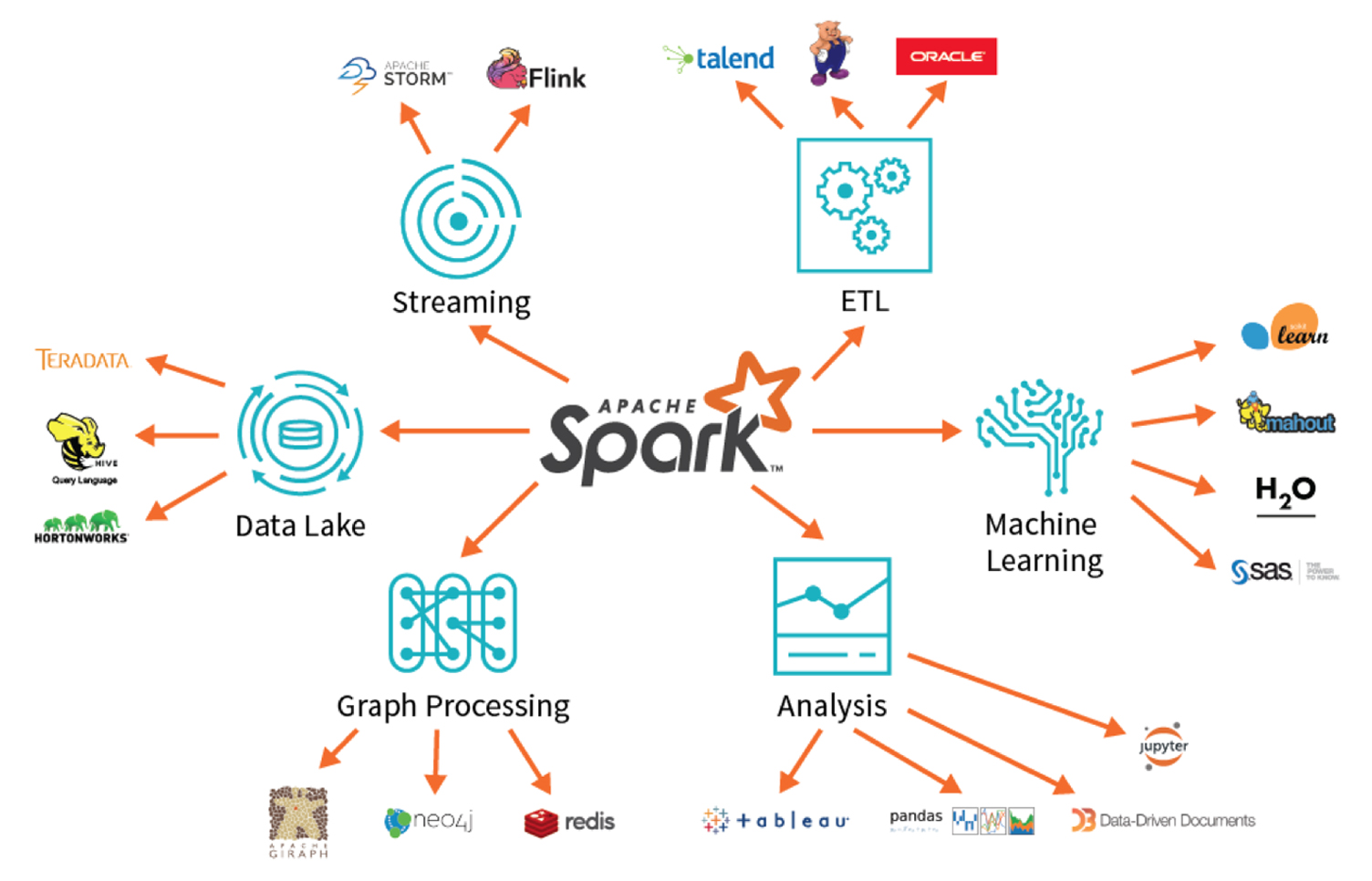
Spark provides multiple advantages. It allows running an application on Hadoop cluster much faster than running in memory and on disk. It also reduces the number of read and write operations to disk. It supports various programming languages. It has built-in APIs in Java, Python, Scala so the programmer can write the application in different languages. Furthermore, it provides support for streaming data, graph and machine learning algorithms to perform advanced data analytics.
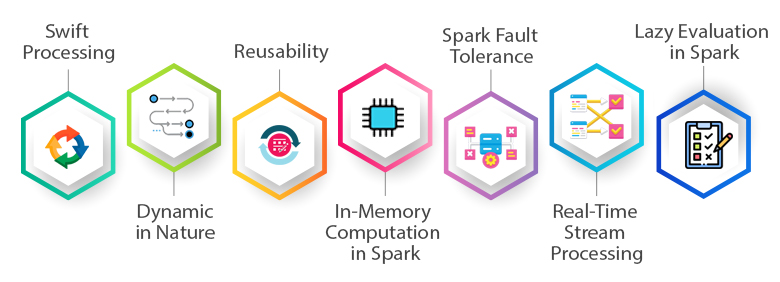
Choose Spark for the following features
Swift Processing
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Dynamic in Nature
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
In-Memory Computation in Spark
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Reusability
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Spark Fault Tolerance
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Real-Time Stream Processing
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Lazy Evaluation in Spark
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
Why do we need Spark?
Spark uses Micro-batching for real-time streaming. Apache Spark is open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop Map Reduce, it also works with the system to distribute data across the cluster and process the data in parallel.
